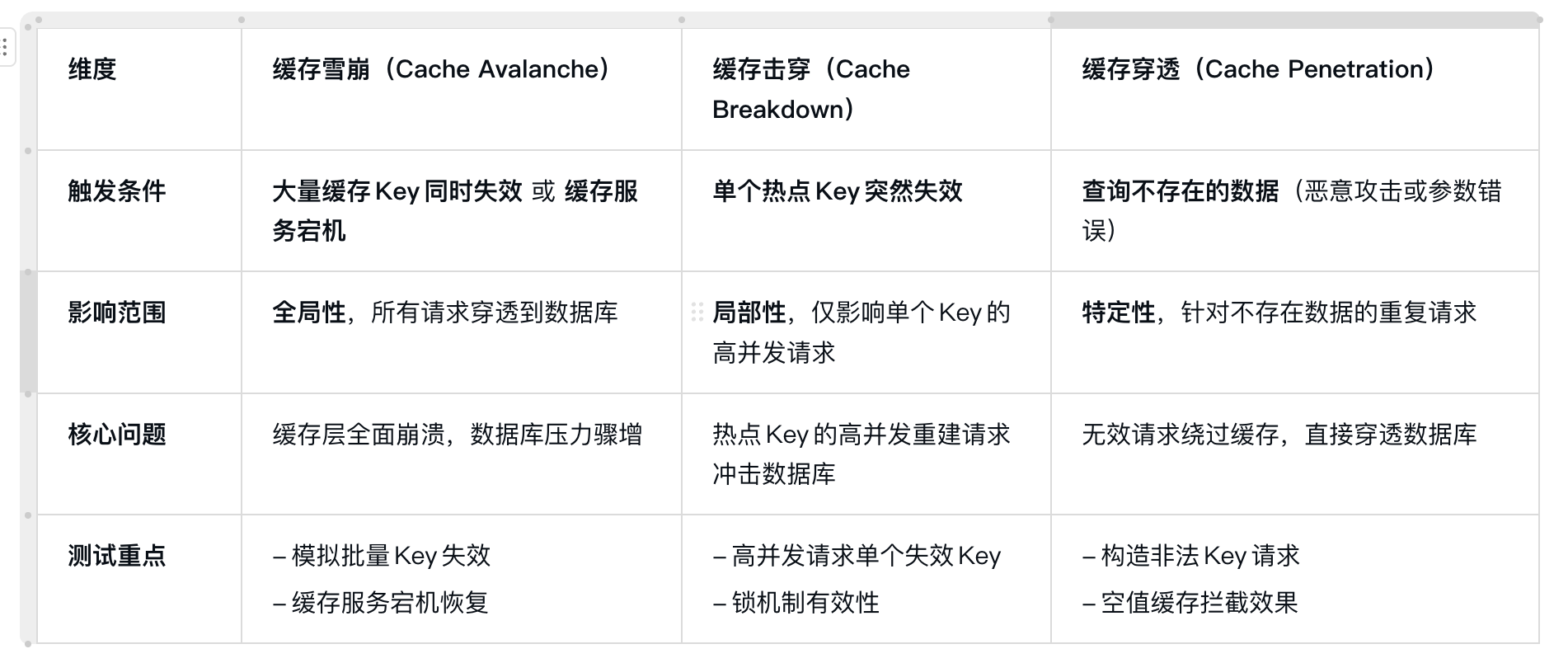
最近在学习性能测试方案,了解到缓存雪崩,缓存击穿和缓存穿透三个概念,针对学习内容在这里做个总结,以便于之后再遇到对于缓存相关的测试方案时能够参考。
缓存雪崩:
缓存中 大量数据在同一时间内过期 或者 缓存服务宕机,导致大量请求直接落在数据库上,从而引起的数据库压力过大,可能会导致系统崩溃
场景:
批量key过期(缓存中大量Key设置相同的过期时间)
缓存服务宕机 (Redis集群因网络故障、硬件问题或过载导致不可用)
冷启动缓存失效(系统重启后缓存全部失效,并且没有缓存预热)
解决方案:
采用分布式锁
测试重点:
对于缓存雪崩的情况,我们需要考虑 如果出现缓存雪崩后 数据库的抗压性(QPS和连接数承载能力)
缓存服务宕机后,是否有合理的恢复机制。
数据一致性:缓存过期后,数据库数据变更,缓存新建后能否同步最新数据
测试方案:
前置构建大量的缓存数据,模拟高并发请求,脚本运行开始时间定在缓存数据淘汰前1分钟,脚本结束时间定在缓存数据淘汰后1分钟。
1. 模拟批量Key失效
步骤:
准备数据:向Redis写入1000个测试Key,设置相同过期时间(如5秒)。
触发失效:等待Key集体过期,或执行
FLUSHDB清空缓存。模拟请求:使用JMeter模拟5000并发用户随机访问这些Key。
监控指标:
数据库QPS、CPU使用率、连接数。
缓存命中率、服务响应时间。
2. 模拟缓存服务宕机
步骤:
正常阶段:运行系统,确保缓存命中率正常。
宕机阶段:手动关闭Redis服务,观察系统行为。
恢复阶段:重启Redis,检查缓存是否自动重建。
监控工具:
Prometheus + Grafana:实时监控数据库和缓存指标。
3. 数据一致性测试
步骤:
缓存失效期间修改数据:
手动更新数据库中的某条记录(如将库存从100改为50)。
触发缓存重建:访问该Key,检查缓存是否读取到最新值。
验证结果:
缓存值是否与数据库一致。
是否存在脏读(如缓存未更新时读到旧值)。
缓存穿透:
指的是 高并发下 查询不存在的缓存数据,由于缓存没有命中,导致请求穿透缓存直接查询数据库,从而引起的数据库压力过大。
场景:
恶意攻击(随机生成 缓存中不存在的数据)
参数异常(前端传入非法参数)
解决方案:
缓存空值
布隆过滤器(Bloom Filter):当请求到缓存层,先通过 过滤器判断Key是否合法
增加入参校验
测试重点:
模拟大量非法key请求
测试方案:
设计 事务不会查询到缓存数据,再进行高并发请求,持续2分钟即可。
构造非法请求key,通过Jmeter 模拟高并发请求
监控 : 缓存的命中率(应该为0%),数据库 QPS 和连接数 不会激增
检查 非法请求能够被Bloom Filter 过滤
缓存击穿:
是指 某一热门缓存突然过期,导致导致大量请求同时穿透到数据库。
场景:
秒杀商品的缓存Key过期
热门新闻详情页的缓存失效。
解决方案:
互斥锁:当缓存过期时通过分布式锁,让其中一个请求进行缓存重建,其他请求等待。(缺点是 锁竞争可能会增加延迟)
逻辑过期: 缓存永不过期,但存储数据时附加一个逻辑过期时间。后台线程定期检查并异步更新。(缺点是 数据一致性较差,可能需要短暂容忍旧数据)
热点数据缓存永不过期:对极热点数据(如首页推荐)设置永不过期,通过定时任务或数据变更事件主动更新缓存。
测试重点:
模拟单个热点Key的高并发请求
测试方案:
提炼当前业务逻辑中存在的缓存失效情况,再模拟缓存失效场景。针对失效的数据进行高并发请求。
先在缓存中写入一个热点数据key,并设置2s 过期
使用Jmeter 模拟高并发,请求该key
监控:数据库的QPS 只有少量增加, 缓存能够重建
核心区别