
近期在学习性能测试相关内容,之前在公司只看到过基于grafana的服务器资源监控平台,但是不知道具体的工作原理,因此想自己尝试搭建一个服务资源监控平台并学习一下通过grafana是如何实现服务器资源监控的。
背景知识
Grafana、Prometheus 和 Node Exporter 是监控系统中常见的三个核心组件,它们协同工作实现资源监控。我需要先了解一下这三个组件是做什么的,各自的工作原理是什么。
Node Exporter:数据采集
作用:
Node Exporter 是 数据采集代理,部署在需要监控的机器(如服务器、虚拟机)上,负责收集 主机层级的硬件和操作系统指标,例如:
CPU、内存、磁盘使用率
网络流量、磁盘 I/O
系统负载、进程状态
工作原理:
以守护进程(Daemon)形式运行,默认通过
9100端口暴露 HTTP 接口。当 Prometheus 请求数据时,Node Exporter 返回当前主机的实时指标(以
metrics格式)。
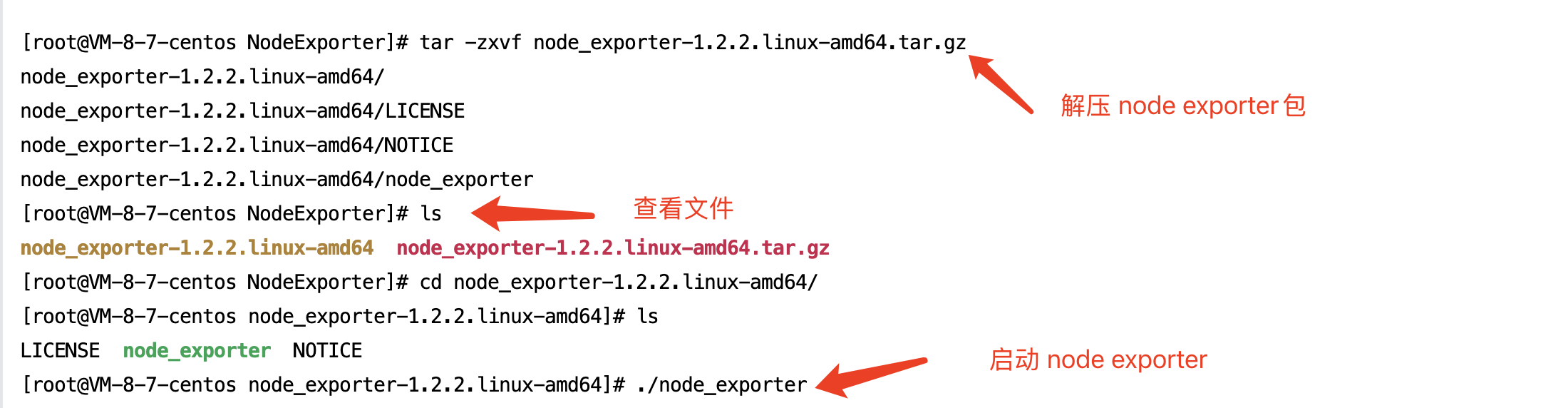
在linux上安装Node Exporter:

Prometheus:数据存储与告警
作用:
Prometheus是一个开源的监控系统和时序数据库,用于收集、存储和查询各种类型的指标数据,并且还支持告警机制。
数据收集:定期从 Node Exporter 等目标 拉取(Pull) 指标数据。
数据存储:存储时间序列数据(按时间戳记录的指标值)。
数据查询:提供查询语言(PromQL)分析数据。
告警机制:触发告警规则并推送至 Alertmanager(需额外配置)。
工作原理:
配置采集目标:在
prometheus.yml中定义需要监控的 Node Exporter 地址。定时拉取数据:默认每 15 秒从目标 HTTP 端点获取一次指标,可以在配置文件自行定义拉取频率
数据存储:将采集的指标压缩存储在本地磁盘或远程存储中。
告警判断:通过预定义的规则(如 CPU 使用率 >90%)触发告警。
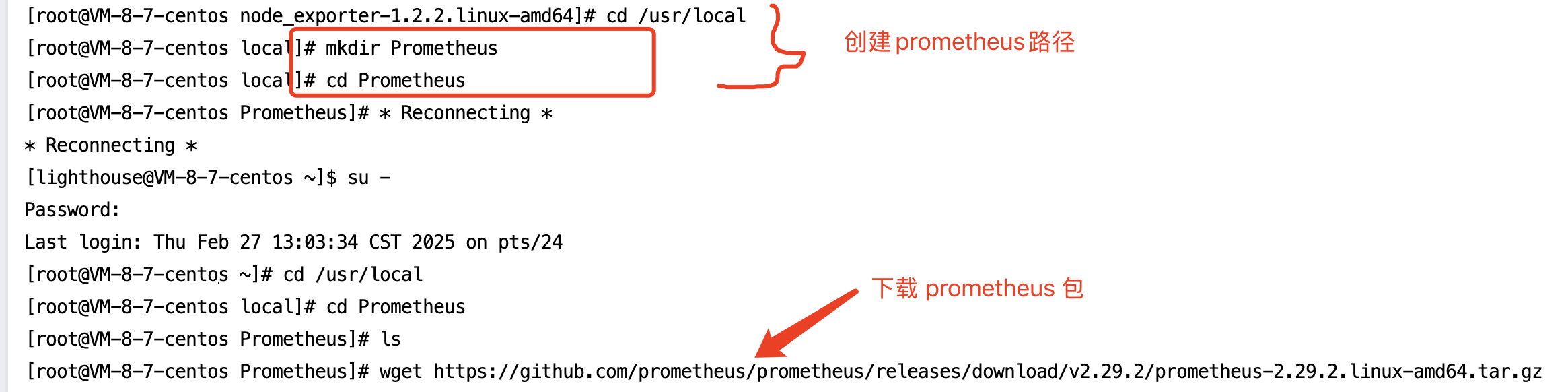
在linux 上安装 Prometheus

修改配置文件
Prometheus 采用 主动拉取(Pull)模型,即由 Prometheus 主动向目标(如 Node Exporter)发起 HTTP 请求获取指标数据。
即使目标在本机,也需要明确配置其地址和端口。
如果目标在其他机器,同样需要配置对应的 IP 和端口。
通过vim /usr/local/prometheus/prometheus-2.29.2.linux-amd64/prometheus.yml 修改配置
scrape_configs:
# 监控 Prometheus 自身的指标(默认已存在)
- job_name: "prometheus"
static_configs:
- targets: ["服务器ip:9090"]
# 新增 Node Exporter 的抓取配置
- job_name: "node_exporter"
static_configs:
- targets: ["服务器ip:9100"] # 本机 Node Exporter 的地址修改配置后,启动prometheus


【注意】如果Node Exporter 不是默认的9100 端口,需要自行修改,确保prometheus.yml中配置的Node Exporter端口正确。
通过web 页面访问 prometheus
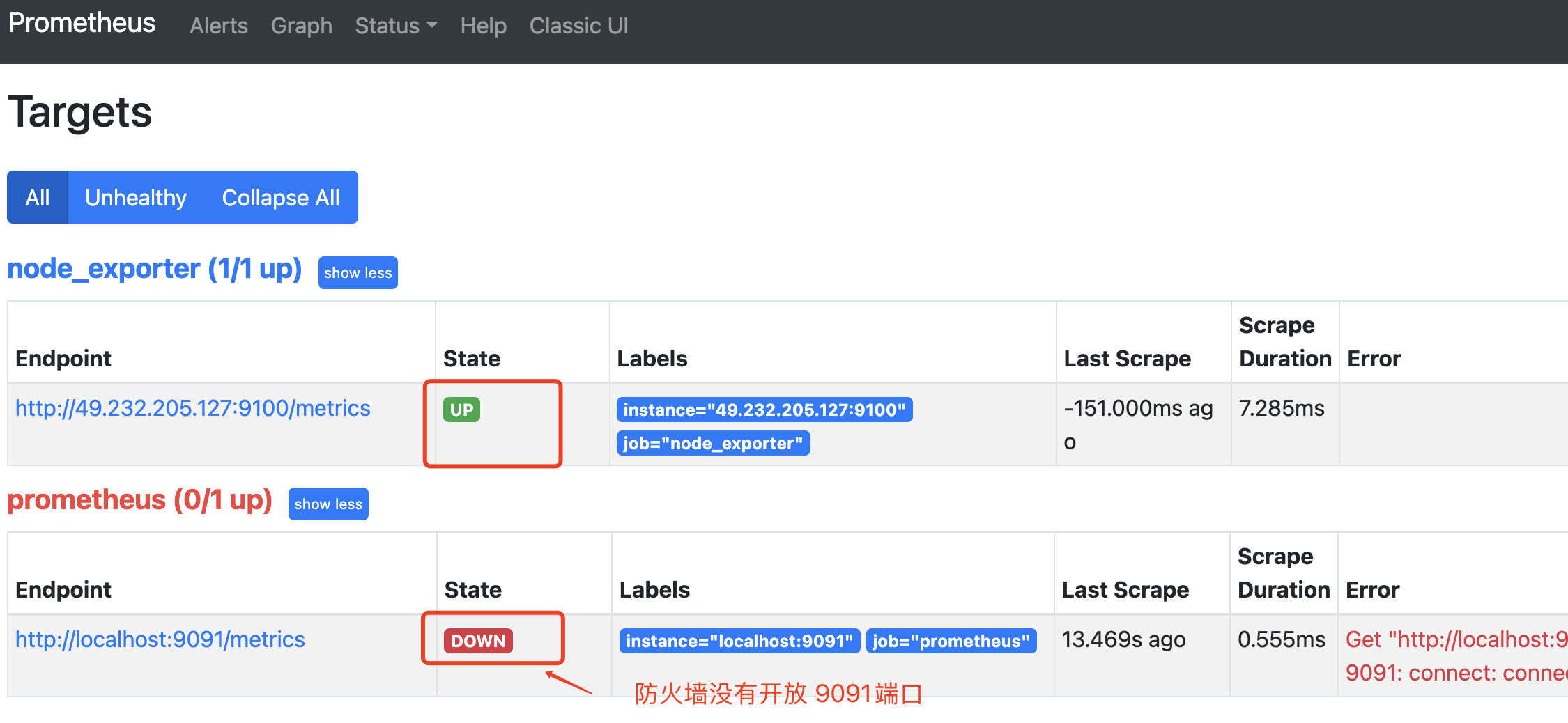
【注意】需要将对应的端口添加在服务器防火墙中 ,否则可能在prometheus 中看到的服务状态为DOWN
Grafana:数据可视化
作用:
Grafana 是 可视化平台,专注于:
从 Prometheus 等数据源读取指标。
通过图表、仪表盘展示监控数据。
自定义告警面板和交互式视图。
工作原理:
连接数据源:配置 Prometheus 作为 Grafana 的数据源(提供 Prometheus 的 URL)。
创建仪表盘:使用 PromQL 查询语句设计图表(如折线图显示 CPU 趋势)。
实时展示:动态刷新数据,支持多维度过滤和时间范围选择。
在linux 服务器上安装grafana:


通过web 界面访问
Grafana 配置:
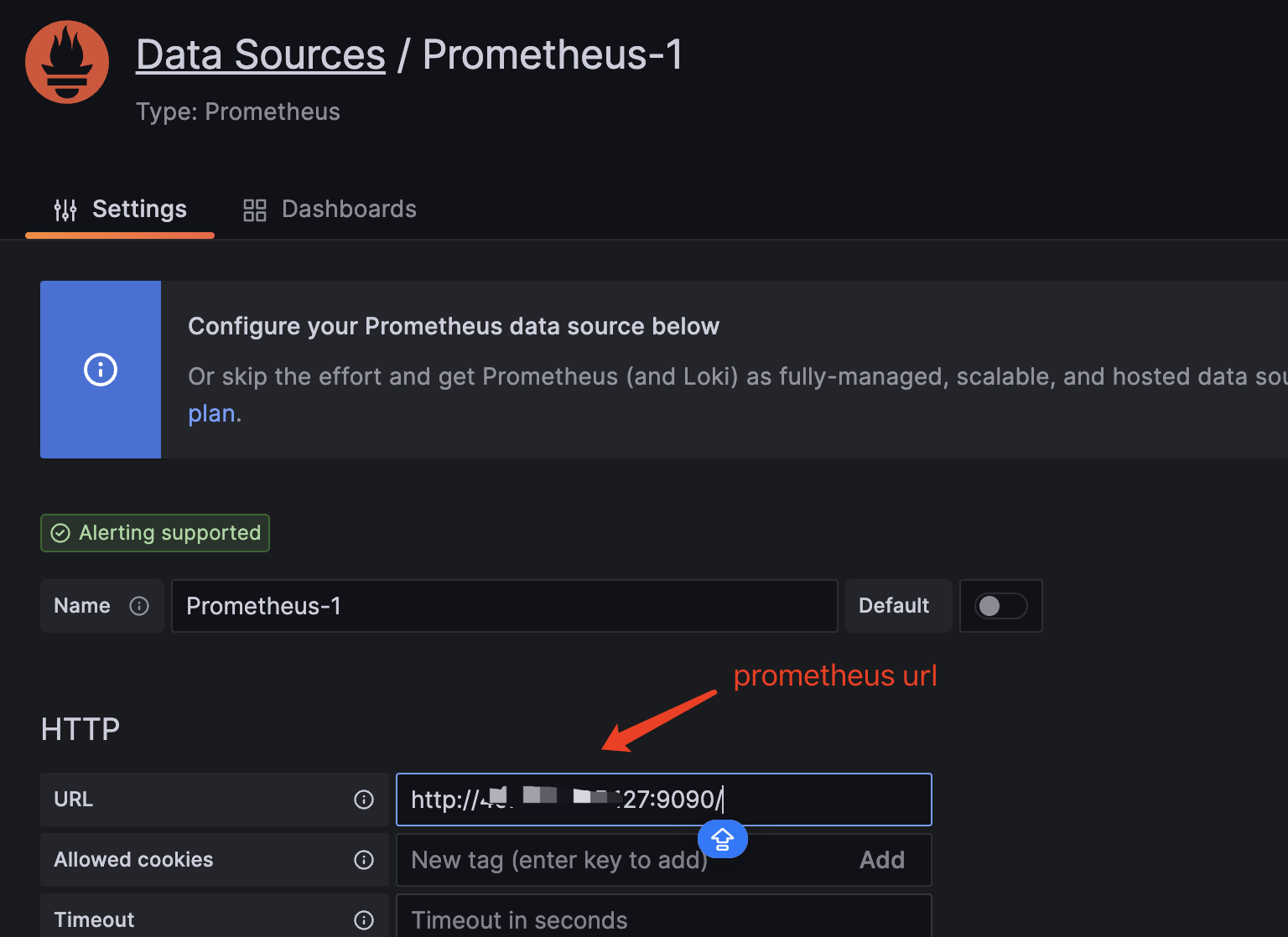
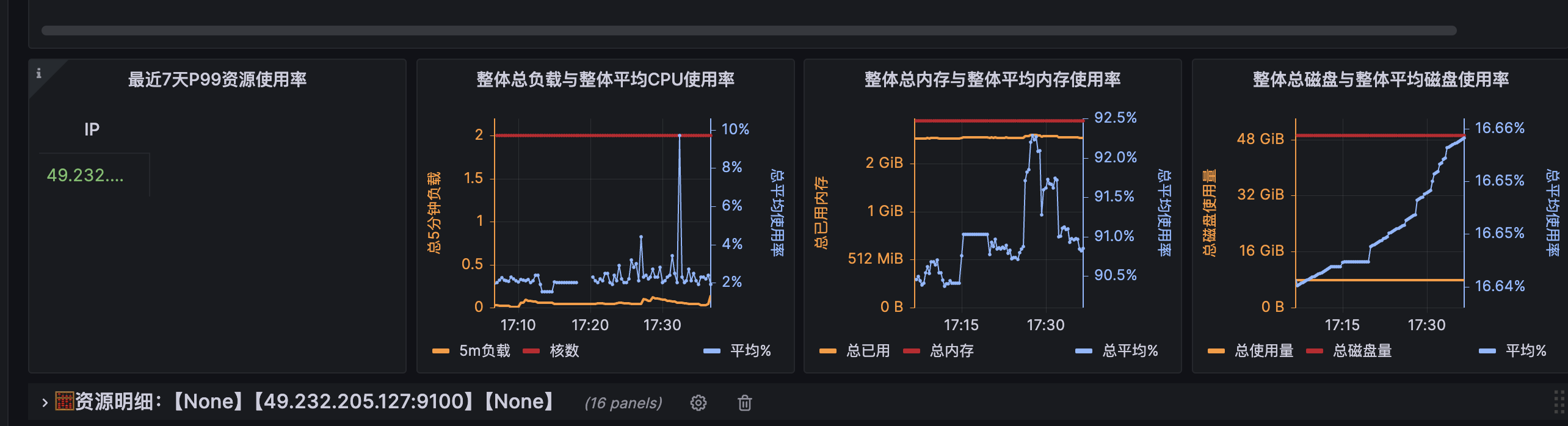
实际效果:
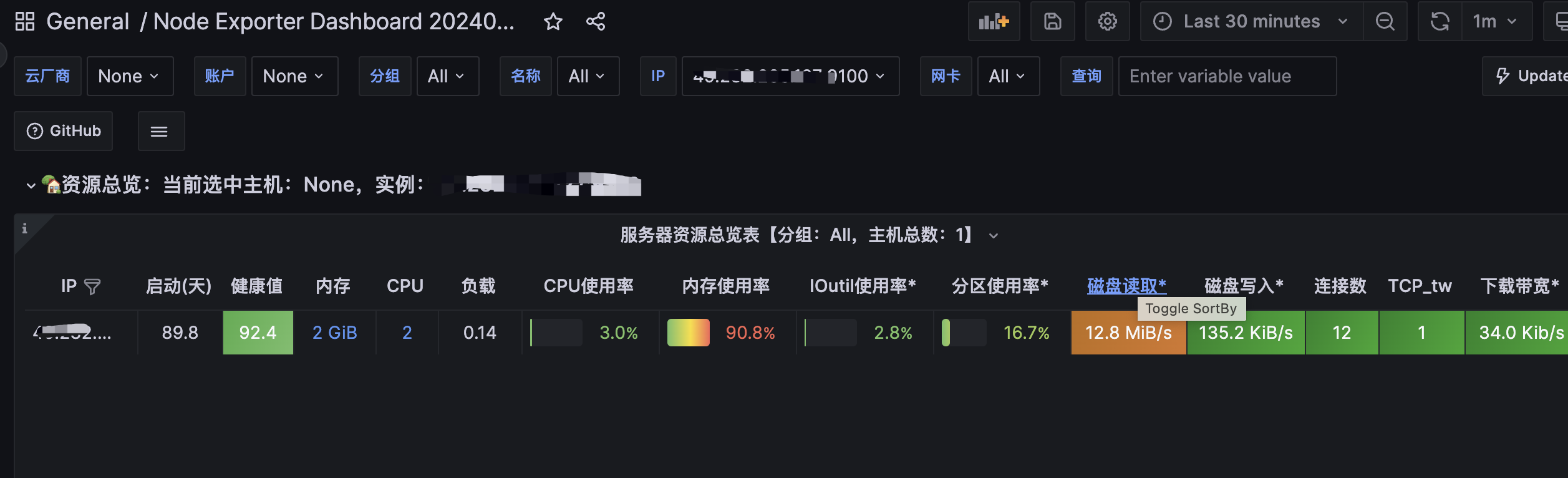
我将这套服务监控都搭建在我的云服务器上,搭建完成后就可以看到我的服务器资源使用情况了,如图:
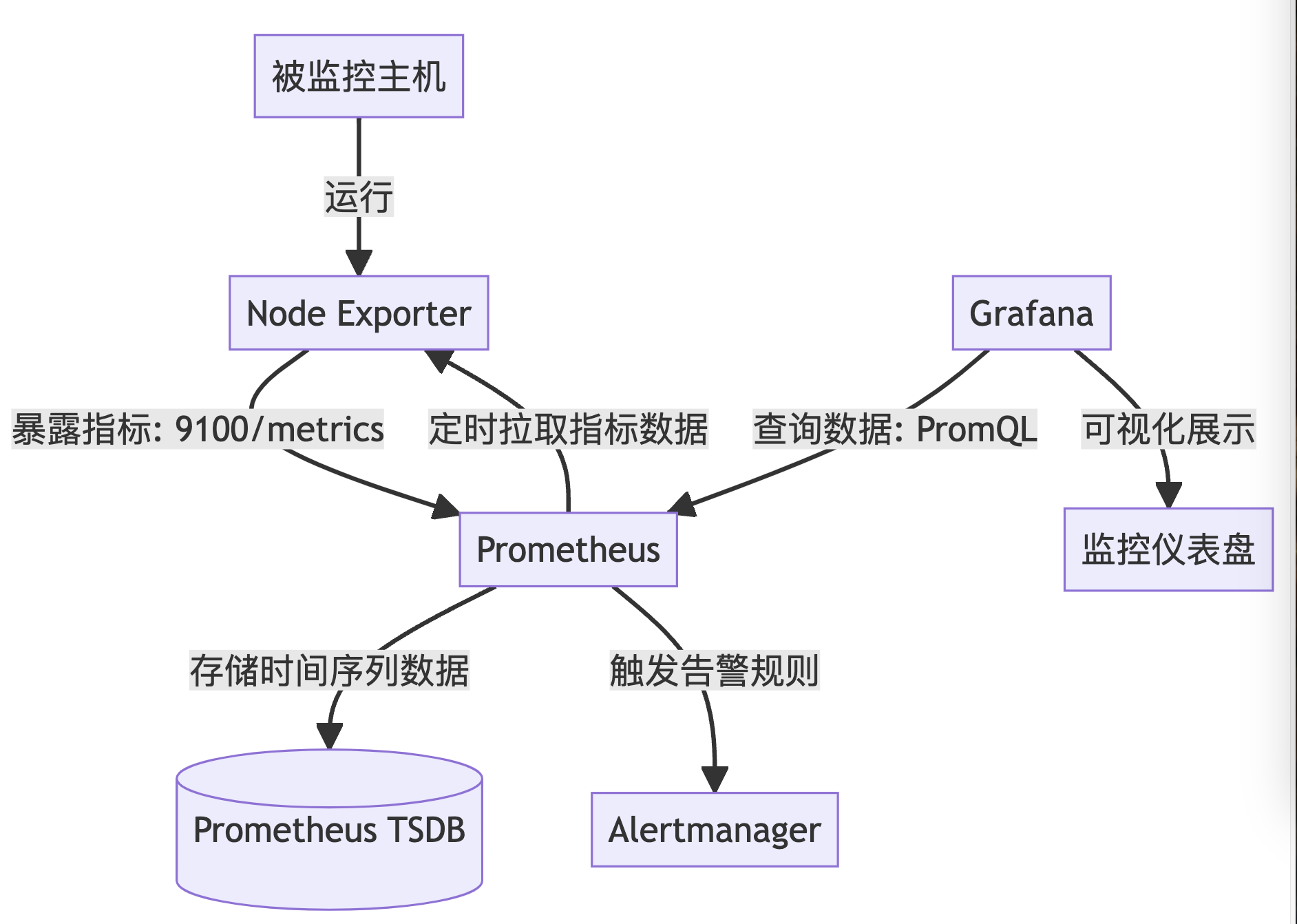
流程图
基于 Grafana + Prometheus + Node Exporter 监控系统的流程图及其分步说明
分步说明
Node Exporter 部署
在被监控主机上运行 Node Exporter(守护进程)。
通过
9100端口暴露指标接口/metrics。
Prometheus 配置与拉取数据
Prometheus 配置文件中定义 Node Exporter 的地址(
prometheus.yml)。Prometheus 定期(如每15秒)主动从 Node Exporter 的
/metrics端点拉取指标数据。
数据存储与告警处理
拉取的数据存储在本地的时序数据库(TSDB)中。
Prometheus 根据预定义的告警规则(如
rules.yml)判断是否触发告警,并通知 Alertmanager(可选组件)。
Grafana 可视化
Grafana 配置 Prometheus 作为数据源(提供 Prometheus 的 URL)。
使用 PromQL 查询语言从 Prometheus 中提取数据,创建图表、仪表盘(如 CPU、内存使用率趋势)。
用户交互
通过 Grafana 的 Web 界面查看实时或历史监控数据,设置阈值告警等。